
Message Classifier
Motivation
The messages that we get on our smartphones are way too cluttered. The inbox has messages from personal numbers, notifications from banks, doctors or even spam numbers. This calls for the need to organize the messages in our smartphone.
Solution
The message classifier provides an easy solution to de-clutter the inbox. The message app automatically classifies the incoming SMS, chats into 3 categories :
- Main/Personal - Comprises of all the personal SMS/chats received from friends, colleagues and personal contacts.
- Notification - This section stacks all incoming notifications and messages- Transaction details, Bank OTPs, ticket details etc.
- Promotion - This section compiles all the promotional offer SMS/message from vivid E-Commerce, telecom or job vendors which are spam or junk.
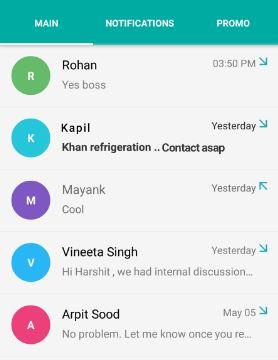 |
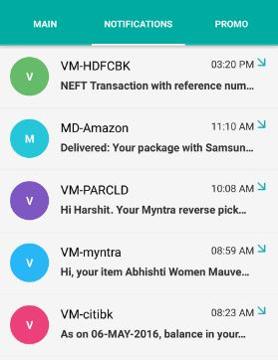 |
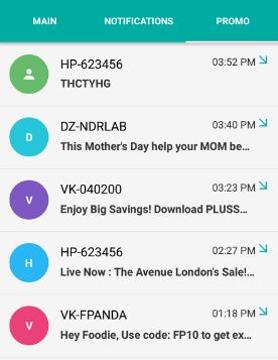 |
Pipeline
- Data Description The message data comprised approximately 10 lakh rows of messages, collected from various people living in India. It consists of the message content, sender’s number and a Boolean field to indicate if the sender is in the user’s contacts.
- Data Pre-processing The raw data was pre-processed as follows :
- Removing tabs, carriages, newlines, punctuation, digits, non-ascii characters and conversion to lower case.
- Making message content consistent - Using Regexes on message content to identify dates, year, months, days, money, web links, emojis, mobile numbers, bank account numbers, time, one time passwords and then substitute them with labels based on their type. The aim behind this is to clean the data without losing information. Eg: A notification message will generally contain bank account numbers. Knowing the value of account number isn’t important but realizing that many notification messages may be from banks and they may contain account numbers is sufficient.
- Preparing Training Data The pre-processed data was further labelled for feeding it to the classifier. It isn’t possible to manually label all the data.
- Instead, the labelling was done based on sender’s mobile numbers, alphanumeric sender codes of varying lengths. This is because personal messages are generally from mobile numbers, whereas promotions and notifications are generally from alphanumeric codes.
- Identifying certain keywords in message content can also be useful in labelling the messages.
- Keywords for Promotion : “best offers”, “cash back”, “free home delivery”
- Keywords for Notification : “main account balance”, “one time password”, “gentle reminder”
- Keywords for Personal cannot be general. People may use different languages, abbreviations. However, the auto-generated messages from personal contacts while the mobile was unreachable were taken as personal messages as well. Those included keywords : “missed call”, ”last call”
- Feature Extraction Features used for classification are the TF - IDF (Term Frequency – Inverse Document Frequency) scores extracted for the messages across the 3 categories (personal, promotion, notification). Also, the regexes developed to identify patterns/ keywords in message content and patterns in sender numbers were used as features with Boolean value. This is because there are fixed sender numbers that are responsible for sending notifications, promotions and they are mutually exclusive.
- Classification 70% data was kept for training and remaining 30% for testing. A hierarchical classification is used, wherein, the first classifier classifies the messages as personal and non-personal. The second classifier further classifies the non-personal messages as notification and promotion. This was done because identifying personal messages from a pool is easier.
- Both classifiers are binary Passive Aggressive Classifiers (PAC).
- Passive Aggressive Classifiers are passive if a data point is correctly classified and will not change the model. They are aggressive if they encounter an incorrect classification.
- Reason for choosing PAC is that it is computationally much faster and space efficient compared to batch learning algorithms. Moreover, data used for training is huge in this scenario. This would mean, even a single pass over the entire data is time consuming, making PAC a favorable option.
- Classifiers such as Multinomial Naïve Bayes gave similar accuracy though not as high as achieved with PAC. PAC could adapt well to unseen, new data.
Results
The classifier performs well in classifying the messages with a high accuracy and recall as shown.
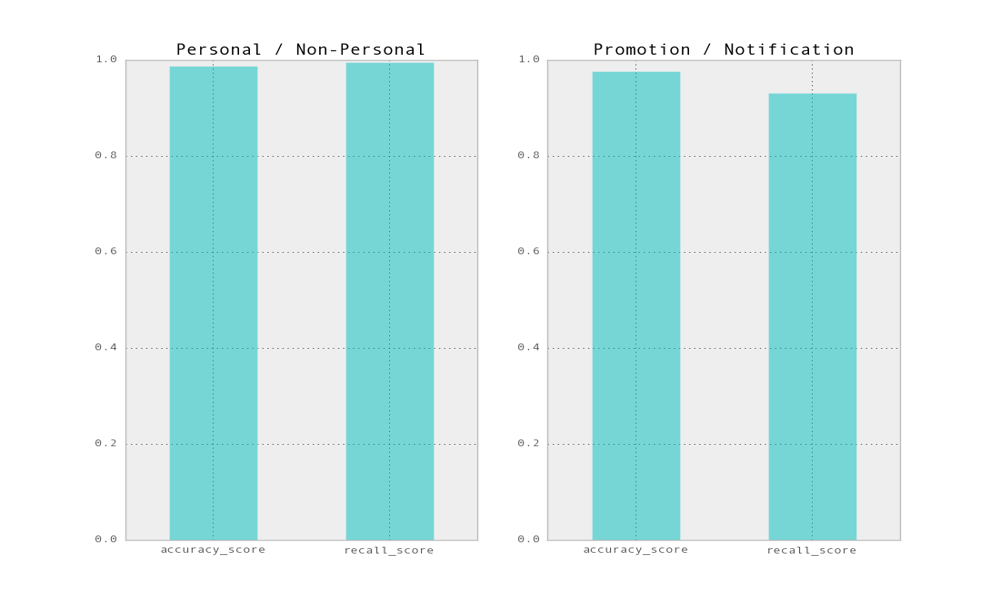
Challenges
- Regexes can break. If the sender changes format of messages sent, it may become difficult to construct robust features and also, prepare reliable tags for training data messages.
- There are certain messages that are difficult to classify as they are written in regional languages, and use slang.
- Promotion and notification messages are particularly challenging to classify as their sender numbers don’t have a clear distinguishing pattern always. This coupled with no clear demarcating keywords in messages makes it harder to classify them.
- When personal messages have content similar to promotion, or, notification messages – This was overcome by taking into account the sender numbers. Personal messages generally have a certain length and are all numeric. They are also generally stored in contacts of the receiver.
Future Work
- Trying other feature extraction methods to build robust features.
- Reduce reliance on regexes once we have sufficient labeled training data. Then possibly, an ML model could be used to extract information out of these messages and reduce dependence on regexes.
- Try non-linear models instead of linear classifiers for classification between notification and promotion messages.